By 2028, 33 percent of enterprise software applications will include agentic AI capabilities, up from less than 1 percent in 2024, according to Gartner. Most of the organisations racing to capture that opportunity are still pricing their AI infrastructure against a cost model that Microsoft quietly broke in September 2025. A 6.17x speedup over standard inference. An 82.2 percent drop in energy consumption. A 100-billion parameter model running on a single consumer CPU with no GPU required.
That result came from Microsoft's 1-bit LLM research, and the numbers stopped the AI community cold. The 1-bit LLM shift changes how much AI costs to run, where it can be deployed, and which agencies understand the infrastructure your next project actually requires. Business leaders who grasp this early will ask sharper questions, negotiate smarter contracts, and hire the right technology partners before their competitors understand what they missed.
This guide explains what a 1-bit LLM is in plain language, why Microsoft's BitNet b1.58 model represents a genuine turning point, what the business implications are across cost, speed, and deployment, and specifically what questions you should be asking any AI agency in 2026. PrimeFirms lists the world's top 5 percent of AI-capable tech firms. The agencies on our platform are already building with these models, and the businesses hiring them deserve to understand what that means for their projects.
What You Will Learn
- What Is a 1-Bit LLM and Why Is Everyone Talking About It?
- Why Standard LLMs Cost So Much to Run and What Changed
- How 1-Bit LLMs Actually Work: The Business-Friendly Explanation
- What 1-Bit LLM Means for AI Costs, Speed, and Accessibility in 2026
- Which Industries Will Benefit First from 1-Bit LLM Technology
- What Businesses Should Ask Their AI Agency About 1-Bit LLMs
- Common Misconceptions About 1-Bit LLMs That Could Cost You
- How PrimeFirms Helps You Find AI Agencies Built for What Comes Next
- Frequently Asked Questions About 1-Bit LLMs for Business Leaders
What Is a 1-Bit LLM and Why Is Everyone Talking About It?
A 1-bit LLM is a large language model where every internal weight.The billions of numerical values the model uses to generate text is stored as one of just three numbers: negative one, zero, or positive one. Standard AI models store those same weights as 16-bit or 32-bit floating-point numbers. The difference in memory this creates is enormous, and so is the difference in what hardware you need to run the model.
Microsoft's research team released BitNet b1.58, their flagship 1-bit LLM, in April 2025. The name comes from the math: encoding three possible values requires log base 2 of 3, which equals approximately 1.58 bits. The model carries 2 billion parameters, was trained on 4 trillion tokens of text, and on head-to-head benchmarks it matches full-precision models of similar size while using a fraction of the compute.
BitNet hit the number one spot on GitHub trending in January 2026 and accumulated over 25,000 stars within days. This was not a slow academic rollout. The developer community recognised immediately that something had changed, and the business world is only beginning to catch up to what that means for AI projects, infrastructure costs, and the kind of agencies worth hiring.
Why the Phrase "1-Bit" Is Slightly Misleading
Technically, these models use ternary encoding three values rather than two, which is what true binary one-bit would give you. The term 1-bit LLM has stuck in practice because the approach traces back to earlier binary quantization research. What matters for business purposes is the outcome: model weights that compress from 16 bits to roughly 1.58 bits per parameter, and the computational advantages that compression unlocks.
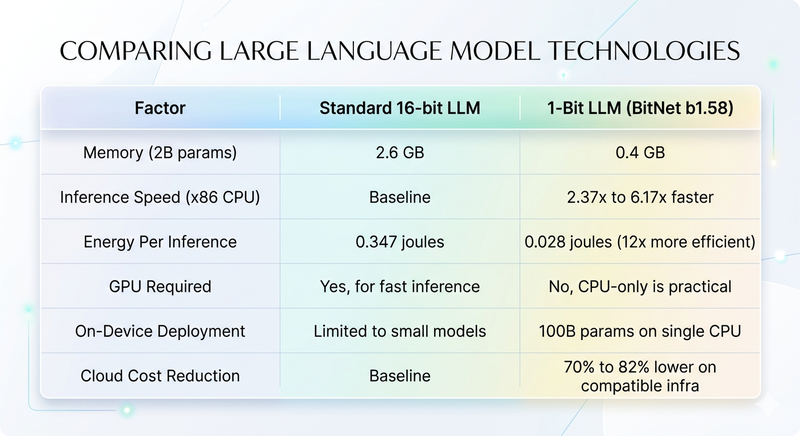
A 7-billion parameter model in standard 16-bit format takes up approximately 14 gigabytes of memory, which is more than most laptop GPUs hold. The same model in 1-bit format fits in under 2 gigabytes. Microsoft's 2-billion parameter BitNet model runs in 0.4 gigabytes. That compression is what makes running serious AI on a standard CPU not just possible but genuinely fast.
The GitHub Moment That Signalled a Shift
When a technical project reaches number one on GitHub trending, it means engineers across thousands of companies are simultaneously recognising something worth paying attention to. BitNet's January 2026 moment was that kind of signal. It joined a short list of projects that developers treated as infrastructure rather than experiment, the same distinction that separated llama.cpp from dozens of other local inference tools when it emerged in 2023.
The agencies that build AI products for businesses are already deploying BitNet in edge computing, mobile AI, and privacy-sensitive applications. In our experience evaluating AI firms for the PrimeFirms platform, the teams that move earliest on infrastructure shifts like this are the ones that deliver the most durable production systems. Business leaders who understand what this shift enables will hire better and negotiate smarter from this point forward.
Why Standard LLMs Cost So Much to Run and What Changed
Running GPT-4 for one million tokens costs approximately $30 on OpenAI's API, according to their published pricing as of Q1 2026. Run that at enterprise scale across a product used by tens of thousands of customers daily, and the compute bill becomes one of the largest line items in your technology budget. AI infrastructure cost is the number one concern among CTOs evaluating large-scale AI deployments, according to McKinsey's 2025 Technology Trends Report.
Standard large language models use floating-point arithmetic for every inference operation. When a model responds to a query, it performs billions of matrix multiplications, each involving 16-bit or 32-bit decimal numbers. The mathematics requires dedicated GPU hardware, which is expensive to buy, expensive to rent, and expensive to run in terms of electricity. GPU clusters that power frontier AI models consume as much electricity as small towns.
The global spend on AI infrastructure reached $220 billion in 2025, according to IDC. A substantial portion of that is GPU compute. Every dollar businesses spend renting cloud GPUs for AI inference is a dollar that does not go toward product development, customer acquisition, or hiring. The cost structure of standard LLMs has forced a trade-off that most small and mid-size companies have not been able to resolve.
What 1-Bit Changes About the Cost Equation
When model weights are stored as negative one, zero, or positive one, the matrix multiplication that drives inference transforms completely. Multiplying by one is just an addition. Multiplying by negative one is a subtraction. Multiplying by zero does nothing at all. The expensive floating-point multiplications that dominate standard LLM compute disappear entirely and get replaced by integer additions and subtractions.
On a 7-nanometer chip, this transformation reduces the energy per arithmetic operation by a factor greater than 70, according to Microsoft Research's published estimates. In practical terms, x86 CPU inference with BitNet runs 2.37 to 6.17 times faster than standard inference and uses 71.9 to 82.2 percent less energy. ARM CPUs, which power most smartphones and a growing share of laptops, show 1.37 to 5.07 times faster inference with 55 to 70 percent energy reduction.
The GPU Dependency Problem and Where It Goes
The AI industry built its current infrastructure on the assumption that bigger models need bigger GPUs. NVIDIA's H100 GPU, the chip that powers most frontier AI today, costs between $25,000 and $40,000 per unit. Training a 70-billion parameter model on standard H100 clusters costs millions of dollars before you write a single line of product code. This has concentrated serious AI development inside a small number of very large companies.
BitNet's architecture does not eliminate GPUs from AI development. Training still requires GPU clusters, and Microsoft released GPU inference support for BitNet in May 2025. What 1-bit LLMs change is the inference side of the equation.Which is where businesses spend most of their ongoing AI costs. Inference is every time your product queries the model to generate a response. Getting that down to CPU-level compute removes one of the biggest structural barriers to AI at scale.
How 1-Bit LLMs Actually Work: The Business-Friendly Explanation
Standard AI models store their knowledge as billions of floating-point weights, each a precise decimal number like 0.7231 or negative 1.4892. During inference, the model processes your input through these weights layer by layer, performing matrix multiplication at each step. The precision of those weights is what makes the model capable, and the expense of doing floating-point math at that scale is what makes inference so compute-intensive.
BitNet replaces those decimal weights with ternary values. Each weight becomes negative one, zero, or positive one. The model is not quantized from a full-precision model after training.Which is the approach most compressed models use and which always degrades quality. Instead, BitNet is trained from scratch using a process called quantization-aware training, where the model learns to represent its knowledge accurately within the tight constraint of three possible values per weight.
The result is a model that is genuinely native to the 1-bit format rather than a shrunken version of something that used to be larger. That distinction matters enormously for quality. Post-training quantization.The common approach where you take a 16-bit model and compress it after the fact.Typically loses measurable accuracy. Native 1-bit training avoids most of that loss because the model learns to work within the constraint from the start.
BitLinear Layers and What They Replace
The technical mechanism behind BitNet is a custom layer called BitLinear, which replaces the standard linear layer used throughout transformer models. In a standard linear layer, every input is multiplied by a weight matrix of floating-point numbers. BitLinear replaces that weight matrix with one where every value is constrained to negative one, zero, or positive one. The activations the values flowing between layers stay at 8-bit precision to preserve representational capacity at the layer boundaries.
This combination of 1.58-bit weights and 8-bit activations is what Microsoft calls the 1-bit approach. The model's memory footprint shrinks dramatically because weights take up less than one tenth of their standard 16-bit space. The computation speeds up dramatically because integer addition and subtraction replace floating-point multiplication. The energy requirement drops because integer operations consume far less power than floating-point operations on any processor.
What the Benchmarks Actually Show
Microsoft compared BitNet b1.58 2B4T directly against leading full-precision models of similar size on standard academic benchmarks. On GSM8K, which measures mathematical reasoning, BitNet b1.58 scores 58.38 against Qwen2.5's 56.79 the 1-bit model actually outperforms the standard model on math while using a memory footprint 6.5 times smaller. On WinoGrande, which tests commonsense reasoning, BitNet scores 71.90 against Qwen2.5's 62.83.
The overall average benchmark score shows a minimal gap of approximately 1 point in favor of the full-precision model a remarkable result given that the 1-bit model uses 0.4 gigabytes of memory versus the competitor's 2.6 gigabytes. Energy efficiency is the most striking figure: BitNet uses 0.028 joules per inference against Qwen2.5's 0.347 joules, making it approximately 12 times more energy efficient at comparable quality levels.
What 1-Bit LLM Means for AI Costs, Speed, and Accessibility in 2026
The business implications of 1-bit LLMs fall into four categories: infrastructure cost, deployment scope, product speed, and competitive timing. Each one deserves a clear-eyed look because the temptation is either to overstate what is possible today or to dismiss this as a technical curiosity that does not affect business decisions for years. Both would be mistakes.
Infrastructure Cost: What Changes and When
Cloud AI inference currently costs between $0.50 and $30 per million tokens depending on the model and provider. For a consumer product that handles 10 million user queries per month, that puts AI inference at $5,000 to $300,000 monthly just for the model calls, before you count storage, bandwidth, application servers, or team salaries. Reducing that cost by 70 to 80 percent changes the unit economics of building AI products entirely.
BitNet's efficiency gains only apply when you use Microsoft's dedicated bitnet.cpp inference framework, which was released as open source in September 2024 and updated with GPU support in May 2025. Running the model through standard libraries like Hugging Face Transformers does not deliver the efficiency benefits. Cost savings are real but require intentional deployment choices from the engineering team building your product.
The practical implication for businesses is this: AI projects scoped and budgeted in 2024 using full-precision model inference costs should be revisited. Agencies that understand BitNet deployment can now build equivalent AI features at substantially lower ongoing infrastructure cost. That savings goes straight to your product margin or your ability to serve users at lower price points than competitors running on standard LLM infrastructure.
Deployment Scope: Where AI Can Now Go
The most significant scope change is on-device deployment. A 3-billion parameter BitNet model runs on a Raspberry Pi 5 at 11 tokens per second, demonstrated publicly and benchmarked in early 2026. The 2-billion parameter flagship model runs on an Apple M2 chip at 45 tokens per second. A 100-billion parameter model runs on a single consumer CPU at 5 to 7 tokens per second roughly human reading speed.
For businesses, this means AI features that previously required a cloud connection can now run entirely on the user's device. Healthcare apps can process sensitive patient data without that data leaving the device. Financial applications can run AI-powered analysis without routing transactions through external servers. Industrial IoT deployments can make AI decisions on the sensor hardware itself rather than sending data to cloud inference endpoints.
Product Speed: Latency at the Edge
Cloud AI inference latency typically runs from 200 milliseconds to 3 seconds depending on model size, load, and geographic distance from the inference server. On-device inference with BitNet runs at 29 milliseconds on a modern CPU for the 2-billion parameter model. For user-facing applications where responsiveness is a product quality metric, that difference between cloud latency and local latency is the difference between a feature users reach for and one they tolerate.
Voice assistants, real-time text analysis, and interactive AI tutoring all benefit directly from sub-50-millisecond local inference. These are product categories where cloud-dependent AI has always felt slightly off the pause before the response breaks the conversational flow. Local BitNet inference removes that pause entirely on capable consumer hardware.
Competitive Timing: The Window That Is Open Right Now
The largest publicly available native 1-bit LLM as of April 2026 is 8 billion parameters. Frontier models from OpenAI and Anthropic operate at orders of magnitude larger. This means 1-bit LLMs are not replacing GPT-4-class reasoning capabilities today. They are replacing the bottom and middle tiers of AI tasks text classification, document summarisation, customer query routing, and light content generation that make up the majority of production AI workloads.
Businesses that identify which of their AI features fall into those categories and rebuild them on efficient 1-bit infrastructure in 2026 will carry a meaningful cost and latency advantage into 2027 and 2028, when the ecosystem matures and larger native 1-bit models become available. The agencies building with these tools now are accumulating the production experience that will matter when scale becomes possible.
Which Industries Will Benefit First from 1-Bit LLM Technology
Four industries are positioned to capture the practical benefits of 1-bit LLMs faster than others in 2026. The common thread is that all four have pressing reasons to want AI that is private, fast, cheap to run, or operable without reliable internet connectivity. That combination narrows the field considerably compared to general AI adoption, which remains dominated by cloud-dependent workloads.
Healthcare: Privacy-First AI at the Point of Care
Healthcare AI has always carried a tension between cloud inference quality and the regulatory requirement to keep patient data within defined boundaries. A GP's tablet running a clinical decision support tool cannot route patient symptoms through a third-party cloud server in most jurisdictions. The same constraint applies to mental health apps, remote patient monitoring devices, and diagnostic support tools in rural clinics with intermittent connectivity.
BitNet's on-device capability resolves this tension directly. A 2-billion parameter medical AI assistant that runs locally on a clinical device with no data leaving the hardware, no cloud dependency, and inference at 45 tokens per second is a product that was not practically buildable at quality in 2024. In 2026, the technical barrier has lowered enough that healthcare software companies and the AI agencies building for them need to be evaluating this architecture seriously.
Financial Services: Compliance and Real-Time Analysis
Financial services firms process AI workloads where two requirements consistently conflict: the need for fast, context-aware analysis and the need to keep transaction data within defined regulatory boundaries. Trading firms want AI that analyses market patterns in real time. Which means local inference where network latency does not introduce timing risk. Banks want AI that processes customer data without that data leaving approved infrastructure, which means on-premise deployment rather than cloud APIs.
1-bit LLMs address both requirements simultaneously. The latency advantage of local CPU inference matters in high-frequency contexts where milliseconds translate directly to execution quality. The on-premise deployment capability satisfies data sovereignty requirements that have blocked broader AI adoption in heavily regulated financial applications. Agencies that understand how to deploy BitNet on financial firm infrastructure will have a clear advantage in winning those mandates.
Manufacturing and Industrial IoT
Industrial environments present conditions where cloud-connected AI breaks down: variable network connectivity, cybersecurity requirements that limit external data transmission, and physical distances from data centres that introduce latency. A quality control system on a production line that routes inspection images to a cloud AI endpoint for every unit produced introduces a bottleneck that affects throughput. A system running local inference on the inspection hardware eliminates that bottleneck entirely.
Predictive maintenance, anomaly detection, and process optimisation are all AI applications where local inference with BitNet becomes viable in 2026. The energy efficiency advantage is particularly relevant in manufacturing, where infrastructure costs include the electricity to run computing hardware around the clock. A 70 to 82 percent reduction in inference energy consumption translates directly to operating cost reduction over the multi-year life of an industrial AI deployment.
Education and Edtech: AI for Every Student
Personalised AI tutoring is one of the most commercially promising AI applications, and also one of the most infrastructure-constrained. Schools in developing markets often lack reliable internet. Individual students cannot afford sustained cloud AI API costs. Devices available to students run on limited hardware budgets. These constraints have limited edtech AI to the wealthiest markets and institutions, despite the strongest educational need sitting elsewhere.
A 2-billion parameter AI tutor running locally on a $150 Android tablet at 20 tokens per second changes the accessibility equation for educational AI. The model never needs an internet connection once downloaded. It costs nothing per query in cloud infrastructure fees. It works in a classroom in rural India or rural Kenya with the same responsiveness it delivers in a well-connected urban school. This is the scope change that 1-bit LLMs make possible.
What Businesses Should Ask Their AI Agency About 1-Bit LLMs
Most AI agencies will not volunteer a conversation about 1-bit LLMs unless you bring it up. This is partly because the technology is recent enough that not every team has hands-on deployment experience with it, and partly because agencies naturally scope projects using the tools they know best. Asking the right questions in discovery conversations tells you a great deal about whether a firm is genuinely current with AI infrastructure or selling expertise they built in 2023.
Need help evaluating whether an AI agency is ready for efficient inference deployments? PrimeFirms verifies every listed firm against a 15-point technical authentication process. Find a vetted AI agency on PrimeFirms.
Question 1: Do You Have Production Experience with BitNet or Similar Efficient Inference?
This question distinguishes firms that have worked with 1-bit LLMs in real deployments from those who have read the same research papers you have. A confident answer should include specific details: which models they deployed, what hardware ran the inference, what use case the efficiency gains served, and what they discovered about the gap between benchmark performance and production behaviour.
A vague answer about being familiar with quantization techniques or having explored efficient AI models is not what you are looking for. Quantization applied after training and native 1-bit training are architecturally different approaches that serve different use cases. An agency that does not distinguish between them clearly is telling you something important about the depth of their current AI infrastructure knowledge.
Question 2: How Would You Evaluate Whether My Project Needs On-Device or Cloud Inference?
This is a scoping question with real budget implications. For workloads where data privacy, offline operation, or latency below 100 milliseconds matter, on-device 1-bit inference is worth serious consideration. For workloads where reasoning quality at frontier model level is the priority, cloud inference with large standard models remains the right answer today. An agency that frames this decision only in terms of what they are comfortable building is prioritising their own preferences over your requirements.
The right answer walks through your specific workload. What data does the model process? Where does that data need to stay? How many queries does the product handle daily, and what is the acceptable cost per query? What response latency does the user experience require? These are the questions that lead to an informed inference architecture decision, and an agency that asks them before proposing a solution has the right thinking.
Question 3: How Do You Stay Current with AI Infrastructure Developments?
BitNet went from research paper to production-ready open-source framework with GPU support in under 18 months. The pace of change in AI infrastructure means that an agency's knowledge base from 2024 may already be a generation behind the best available approaches in 2026. Asking directly how a firm tracks and integrates emerging AI infrastructure reveals whether you are hiring a team that learns continuously or one that builds on a fixed skill set.
Specific signals to look for: do they follow Microsoft Research releases? Have engineers on the team contributed to or experimented with open-source AI infrastructure projects? Can they name the specific trade-offs between llama.cpp, GGUF quantization, and the bitnet.cpp inference framework? These are not trick questions. They are the kind of technical awareness that separates agencies building at the current frontier from those replaying approaches that were current two years ago.
Question 4: What Does 1-Bit LLM Mean for the Long-Term Cost Model of My Product?
An agency that cannot model the long-term infrastructure cost of your AI product under both standard inference and 1-bit efficient inference approaches is missing a fundamental part of product partnership. Ask for a comparison. Show us what annual inference costs look like at 100,000 monthly active users under standard cloud inference. Now show us what those same costs look like under a hybrid approach where eligible workloads route to on-device 1-bit inference. The difference in those two numbers is the size of the opportunity you would miss by not asking.
Common Misconceptions About 1-Bit LLMs That Could Cost You
The hype around 1-bit LLMs is real, and so is the misunderstanding. Business leaders who make decisions based on either the overpromise or the dismissal will spend money poorly. These are the four misconceptions most worth correcting before you sit across from an agency in a project scoping conversation.
Misconception 1: 1-Bit LLMs Replace GPT-4-Class Models
The largest publicly available native 1-bit LLM as of April 2026 is 8 billion parameters and the benchmark gap between that and a 70-billion parameter frontier model on complex reasoning tasks is significant and real. GPT-4 is estimated at well over 1 trillion parameters, and Claude operates at a similar scale. 1-bit LLMs do not replace frontier reasoning capability today.
What 1-bit LLMs replace well today is the category of AI workloads that never needed frontier-scale reasoning in the first place. Text classification, intent detection, document summarisation, structured data extraction, and customer query routing are workloads where a well-trained 2 to 8 billion parameter model handles the task adequately. A large portion of production AI workloads fall into this category which is exactly where the cost and latency advantages of 1-bit architecture apply immediately.
Misconception 2: The Efficiency Gains Apply Everywhere
BitNet's efficiency gains only materialise when you use the dedicated bitnet.cpp inference framework. Running a BitNet model through standard Hugging Face Transformers or a generic PyTorch setup will not deliver the 6x speedup or the 82 percent energy reduction. The specialised kernels that handle 1-bit arithmetic are what produce the efficiency. Standard frameworks do not include those kernels because they were designed around floating-point computation.
This is a genuinely important technical constraint to surface in any project scope conversation. An agency that proposes deploying a BitNet model without a clear plan for the inference framework is either not familiar enough with the actual deployment requirements or is describing a setup that will not deliver the cost and latency benefits you are paying for. Ask specifically: which inference framework are you planning to use, and how does that choice affect the efficiency metrics?
Misconception 3: Any Developer Can Deploy This Easily Right Now
BitNet deployment is more complex than standard model deployment. The bitnet.cpp framework requires platform-specific compilation, and the setup process differs between Linux, macOS, and Windows environments. Optimising inference for specific hardware architectures. Whether ARM or x86 requires understanding the parallelism model that the framework uses. Optimising kernel implementations with configurable tiling for maximum throughput on a specific CPU microarchitecture is specialist work that takes real production experience to get right.
This is not a reason to avoid 1-bit LLMs. It is a reason to choose an agency with engineers who have worked through these deployment challenges in real projects. The learning curve is front-loaded teams that have already done it once have a significant advantage over teams starting from scratch on your budget and timeline.
Misconception 4: This Technology Is Too New to Trust
Microsoft's BitNet research began in 2024 with the original BitNet paper. The b1.58 variant with ternary weights published in February 2024. The full open-source inference framework launched in September 2024. The 2-billion parameter open-weights model trained on 4 trillion tokens released in April 2025. GPU inference support landed in May 2025. A CPU optimisation update shipped in January 2026. This is not a research paper from last month this is a technology with 18 months of open-source development, community testing, and production deployments behind it.
The developer community's confidence, evidenced by 25,000 GitHub stars and active production use in edge computing, healthcare, and mobile AI applications, reflects real testing rather than speculative enthusiasm. Treating this as too new to evaluate in 2026 is the same mistake organisations made about cloud infrastructure in 2010 and mobile-first development in 2012. The window to build early operational experience is open now.
How PrimeFirms Helps You Find AI Agencies Built for What Comes Next
PrimeFirms lists only the top 5 percent of software, AI, and technology agencies globally. Every firm on the platform has passed a 15-point authentication process covering portfolio quality, verified client reviews, technical credentials, delivery track record, and ongoing performance monitoring. Of 24,353 agencies that have applied, fewer than 1 in 20 meets the standard for listing.
When you search for an AI development firm on PrimeFirms, you are not browsing a directory of self-submitted profiles. You are looking at agencies that have demonstrated consistent delivery across complex technical projects including AI infrastructure, LLM integration, edge computing, and the kind of production deployment experience that separates firms capable of building with 1-bit LLMs from those still catching up on transformer architecture basics.
Finding the right AI partner for a project that might involve efficient inference, on-device AI, or LLM-powered features starts with knowing where to look. PrimeFirms built its ranking methodology specifically to surface the agencies with the deepest technical capability and the strongest delivery culture, verified by clients who have already hired them and got results. Start your search on PrimeFirms and find your AI development partner today.
The AI Cost Curve Just Changed and Your Next Agency Should Know It
The 1-bit LLM transition is not theoretical. Microsoft's BitNet is in production, available open source, and actively deployed by teams building real products right now. The efficiency numbers 6x faster inference, 82 percent less energy, 100-billion parameter models on a single CPU are verified against real hardware under real conditions, as of Q1 2026.
We have seen, across the AI firms evaluated for the PrimeFirms platform, that the agencies who move earliest on infrastructure shifts like this are the ones who deliver the most durable, cost-efficient production systems for their clients. The questions you ask your next AI agency will determine whether you build with this advantage or pay full price for infrastructure that the best teams have already started moving past.
PrimeFirms connects businesses with the top 5 percent of AI-capable agencies every one verified for technical depth and delivery record. If your next AI project deserves a partner who understands what comes after the GPU-only era, start your search on PrimeFirms and find that partner today.
Frequently Asked Questions About 1-Bit LLMs for Business Leaders
What exactly is a 1-bit LLM in plain language?
A 1-bit LLM is a large language model where the internal numerical values it uses to generate text called weights are stored as one of only three numbers: negative one, zero, or positive one. Standard models store those same values as 16-bit or 32-bit decimal numbers, which requires far more memory and far more compute-intensive arithmetic to process. The 1-bit approach compresses the model dramatically without destroying quality, because the model learns to work within that tight constraint from the very beginning of training rather than having compression applied after the fact. Microsoft's BitNet b1.58 is the most prominent example in production today, with 2 billion parameters that rival the performance of full-precision models of similar size on standard benchmarks, while fitting in 0.4 gigabytes of memory compared to the 2.6 gigabytes a comparable standard model requires.
How does a 1-bit LLM affect my business's AI infrastructure costs?
The cost impact depends on which workloads you route through a 1-bit model and which infrastructure you use for inference. On x86 CPU hardware with Microsoft's dedicated bitnet.cpp inference framework, energy consumption drops by 71.9 to 82.2 percent compared to standard model inference, and inference speed improves by 2.37 to 6.17 times. For AI features running at scale customer query classification, document processing, content analysis these efficiency gains translate directly into lower cloud infrastructure spend per million queries. For on-device deployments where you avoid cloud inference entirely, the cost reduction is even larger because you eliminate the per-query API fee altogether. The right way to think about this is not as a blanket cost cut but as a targeted efficiency gain for the subset of your AI workloads that do not require frontier-scale reasoning. Most production AI workloads fall into that category.
Can a 1-bit LLM replace the AI tools my business already uses?
For some workloads, the answer is yes. For others, not yet. At their current maximum size of around 8 billion parameters, 1-bit LLMs handle a wide range of practical business AI tasks extremely well: text classification, intent detection, structured data extraction, document summarisation, customer service query routing, simple code generation, and content moderation. For tasks requiring the deep reasoning, nuanced analysis, and broad knowledge of frontier models like GPT-4 or Claude, 1-bit LLMs are not a replacement today. The practical approach for most businesses is a hybrid architecture where workloads that fall within the capability range of efficient 1-bit models get routed to local or on-device inference, and workloads that genuinely require frontier-scale reasoning continue on cloud APIs. This hybrid approach captures the cost and latency advantages where they apply without sacrificing quality where it matters.
Do I need a GPU to run a 1-bit LLM?
No and this is one of the most practically significant things about the technology. Microsoft demonstrated running a 100-billion parameter BitNet model on a single consumer CPU at 5 to 7 tokens per second in 2025. The 2-billion parameter flagship model runs on an Apple M2 chip at 45 tokens per second using CPU-only inference. A 3-billion parameter model runs on a Raspberry Pi 5 at 11 tokens per second. These are not theoretical figures from a controlled lab environment they are benchmarks from public testing on standard consumer hardware. GPU support for BitNet did land in May 2025, which allows even faster inference on GPU hardware for teams that have it available. The CPU-only inference capability is what removes the GPU dependency that has been one of the largest structural barriers to running AI locally on constrained hardware.
What is bitnet.cpp and why does it matter?
bitnet.cpp is Microsoft's official open-source inference framework built specifically for 1-bit large language models. Released in September 2024 and actively updated through 2025 and 2026, it is the tool that actually delivers the efficiency gains that make 1-bit LLMs practical. Built on top of llama.cpp, the widely used open-source inference engine, bitnet.cpp adds specialised computational kernels that handle ternary arithmetic efficiently on both ARM and x86 processors. Without these kernels, running a BitNet model through a standard framework like Hugging Face Transformers gives you no efficiency advantage over a full-precision model. The kernels are what replace floating-point multiplication with integer addition and subtraction at the hardware level which is where the energy and speed gains actually originate. January 2026 brought a further optimisation update with parallel kernel implementations that delivered an additional 1.15 to 2.1 times speedup over the already-improved baseline.
Which industries are best positioned to adopt 1-bit LLMs first?
Healthcare, financial services, manufacturing, and education are the four sectors where the specific advantages of 1-bit LLMs align most directly with existing operational constraints. Healthcare benefits from on-device deployment that keeps patient data local, satisfying regulatory requirements around data sovereignty and privacy. Financial services benefit from the combination of low latency for real-time analysis and on-premise deployment capability for compliance-sensitive workloads. Manufacturing benefits from AI that operates without reliable internet connectivity and at dramatically lower power consumption than standard inference requires. Education benefits from the accessibility of local inference on low-cost devices, which removes the cloud dependency that has limited AI-powered tutoring to connected and affluent environments. Any business with AI workloads that are privacy-sensitive, latency-critical, or operating in bandwidth-constrained environments has reason to evaluate 1-bit inference architecture in 2026.
What should I look for when hiring an AI agency to build with 1-bit LLMs?
Production experience matters more than theoretical familiarity. Ask specifically whether the agency has deployed BitNet or similar efficient inference frameworks in real projects, what hardware those deployments ran on, what use cases the efficiency gains served, and what challenges they encountered between benchmark performance and production behaviour. Agencies with genuine hands-on experience will answer with specifics. Agencies without it will speak in generalities about being familiar with quantization or efficient AI approaches. Beyond technical experience, look for engineers who understand the inference framework choice. The difference between bitnet.cpp, llama.cpp, GGUF quantization, and standard transformer inference and can explain clearly why each fits different production scenarios. PrimeFirms' verification process specifically assesses technical depth across AI infrastructure as part of the 15-point authentication every listed agency passes.
Are there any limitations of 1-bit LLMs I should know before making decisions?
Three limitations are worth understanding clearly. The first is scale: the largest available native 1-bit LLM as of April 2026 is 8 billion parameters capable, but not at frontier reasoning quality. Tasks requiring the depth of GPT-4-class models are not appropriate for 1-bit inference today. The second is training: you cannot convert an existing full-precision model to 1-bit quality by quantizing it after training. Native 1-bit models must be trained from scratch using quantization-aware training, which is more computationally demanding than standard pretraining and limits the number of organisations capable of producing new 1-bit base models. The third is tooling: the efficiency gains require the dedicated bitnet.cpp inference framework, not standard libraries. Teams that want the efficiency benefits must commit to building and maintaining deployment infrastructure around that specific tool rather than the more commonly used alternatives.
How does 1-bit LLM technology affect the cost of building an AI product?
The effect on build cost and on running cost are separate and worth distinguishing. Build cost the upfront development effort may be slightly higher with 1-bit LLMs because the deployment tooling is less mainstream and requires engineers with specific experience. Running cost ongoing inference expenses is where the advantage is substantial. AI products built on standard cloud inference pay per token or per API call on an ongoing basis. Products built on on-device 1-bit inference pay that cost once at model download and nothing per query thereafter. At meaningful product scale, the difference in running cost is large enough to change the unit economics of whether a business model is viable. A product that charges $10 per month per user cannot sustain $8 in monthly cloud inference costs. The same product running on efficient on-device inference may sustain $0.50 in infrastructure per user per month which changes the margin picture entirely.
Where can I find AI agencies that understand and work with 1-bit LLM technology?
PrimeFirms is the most direct answer. The platform lists the top 5 percent of AI development agencies globally, each verified through a 15-point authentication process covering portfolio quality, client reviews, technical expertise, delivery metrics, and ongoing performance. Every listed agency has demonstrated the kind of technical depth that includes staying current with AI infrastructure developments like BitNet. Searching PrimeFirms' AI and machine learning category gives you access to firms that have already built with efficient inference frameworks, on-device AI deployment, and LLM integration at production scale. The verification process filters out agencies that market AI capability without the engineering depth to back it up which is the most common and expensive mistake businesses make when hiring for AI projects in a rapidly evolving technology landscape.